tl;dr
Goals: To analyze the public's Opinion on DNA fingerprinting using publicly available tweets.
Overview
As DNA and ancestry companies continue to compile millions of genetic information samples into a database, controversy surrounding whether or not this is ethical. In fact, Ancestry and 23andMe have collectively obtained more than 26 million DNA samples in their databases. (Source). In order to analyze the public’s sentiment on DNA fingerprinting, which is one such application of creating a DNA database, a script written in Python using Google Colab was created to search the Twitter API for a list of keywords
List of technologies used:
tweepy(to search for tweets)gspread(to create database)colab-env(to set environment variables)demoji(to process and clean emojis)textblob(sentiment and subjectivity analysis)nltk(text preprocessing)pandas(to store data before adding to database)re(text and data cleaning)os(to get environment variables)
Querying the Twitter API
- Create a list of keywords to search the Twitter API for.
- Query the Twitter API for 100 English tweets for each keyword in the keyword list before a certain date. The date is changed everyday to query for different results.
- Populate each raw tweet into their corresponding date sheet
*Tweets were queried for each day between 10-09-2021 to 11-03-2021
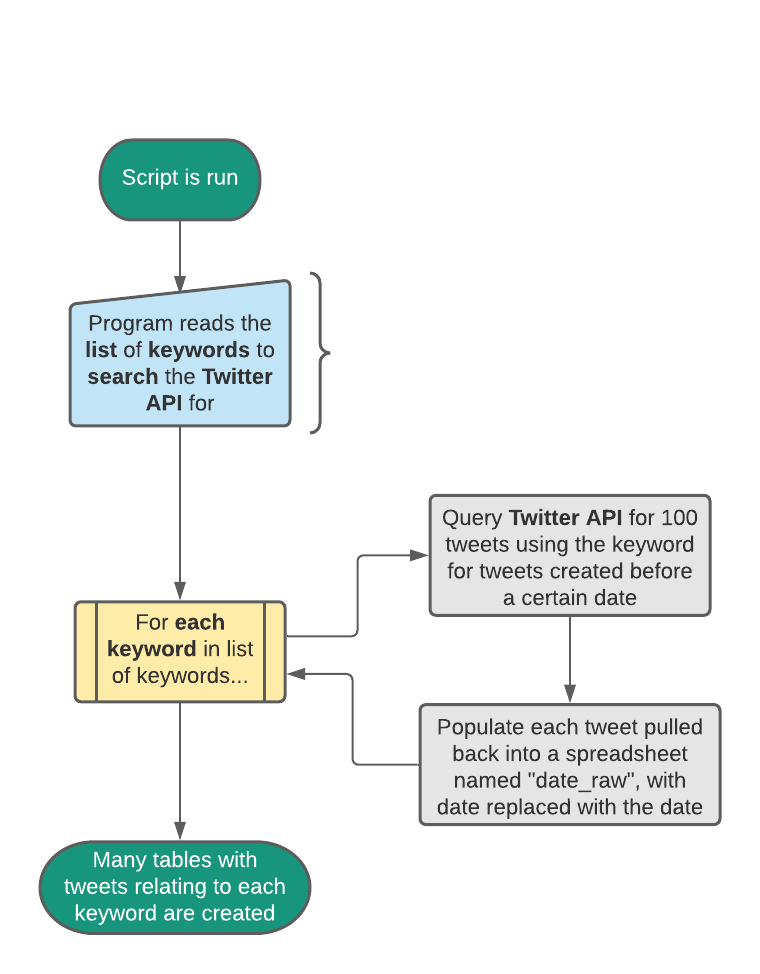
Figure 1: Diagram of steps taken in collecting publicly available tweets.
Data Cleaning
- Go through each sheet with raw tweets collected in Querying the Twitter API.
- For each tweet...
- Replace all URLs with
_IMG - Replace all regular URLs with
_URL - All emojis are replaced with their textual descriptions (🙂 →
Slightly Smiling Face) - All repeated letters are replaced with just 2 letters of the same repeated character
(
heeeeeeeello→heello.
This preprocessing was done in order to prepare tweets for sentiment analysis.
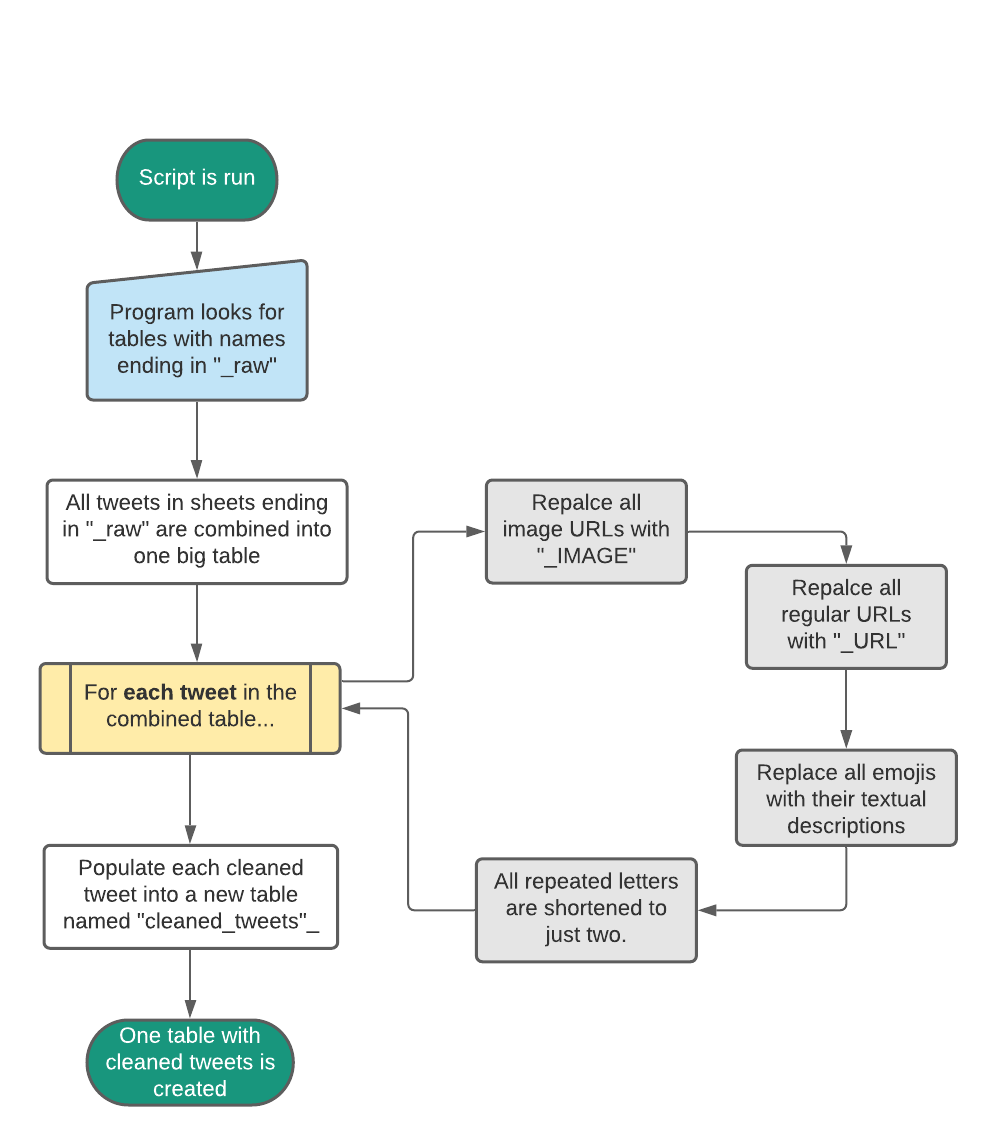
Figure 2: Diagram of steps taken in cleaning tweets.
Example tweet before data cleaning: "We 💚love💚 these photos of some very impressive students learning gel electrophoresis and DNA profiling ... in first year! 🤯 Thank you for sharing the photos @GoreyEtss. We're looking forward to seeing what these scientists do next! #BiotechExperience @ABEProgOffice https://t.co/idow3wAkSd"
Example tweet after data cleaning: ": green heart : love : green heart : photos impressive students learning gel electrophoresis DNA profiling .. first year ! : exploding head : Thank sharing photos @ GoreyEtss . 're looking forward seeing scientists next ! #BiotechExperience @ ABEProgOffice _IMAGE"
Sentiment Analysis
After data collection and cleaning, sentiment analysis was performed on each tweet, allowing us to determine an average sentiment for each keyword we searched for.
| Keyword | Sentiment Score |
|---|---|
| genetic fingerprinting | -0.07 |
| dna profiling | 0.02 |
| dna identification | 0.04 |
| dna typing | 0.05 |
| dna fingerprint | 0.06 |
| genetic profiling | 0.08 |
| dna profile | 0.09 |
| dna fingerprinting | 0.1 |
| genetic profile | 0.1 |
| genetic fingerprint | 0.13 |
Note: sentiment scores ranged from [-1,1] with -1 being the most negative and 1 being the most positive
Through sentiment analysis, it is possible to determine the public's opinion on DNA fingerprinting.
Genetic profiling contained tweets with the most positive sentiment (0.13), while
genetic fingerprinting contained tweets with the most negative sentiment. Taking the
average sentiment across all keywords reveals that the average sentiment is 0.06 This
reflects that the public has a slightly positive sentiment when it comes to discussing DNA
fingerprinting.
Subjectivity Analysis
Subjectivity analysis (how objective or opinionated) was performed on each tweet.
| Keyword | Sentiment Score |
|---|---|
| dna fingerprinting | 0.35 |
| genetic fingerprinting | 0.37 |
| dna profiling | 0.38 |
| dna fingerprint | 0.39 |
| genetic fingerprint | 0.40 |
| dna identification | 0.40 |
| genetic profile | 0.40 |
| dna profile | 0.41 |
| dna typing | 0.43 |
| genetic profiling | 0.45 |
Note: The subjectivity is a float within the range [0.0, 1.0] where 0.0 is very objective and 1.0 is very subjective.
Through subjectivity analysis, it was possible to determine how objective or subjective tweets about a
keyword were. For example, dna fingerprinting contained tweets that were the most
objective (0.35), while genetic profiling contained tweets that were the most subjective
(0.45). Taking the average of all keywords in subjectivity analysis reveals that the average
subjectivity was 0.398. This means that on average, the public typically is more objective
than subjective when it comes to talking about DNA fingerprinting
Results
- The public generally has a positive sentiment when talking about DNA fingerprinting.
- The public generally is more objective than subjective when talking about DNA fingerprinting.
Source Code
The source code, raw data, cleaned data, and analysis results are all published on GitHub in order to promote further research on this topic.
- Code can be found in the
API_Search_and_Analysis.ipynbfile. combined_data.zipcontains all raw tweets both with and without data cleaning.overview_and_keywords.zipare two csv files that give a general overview of the project and detail which keywords the script used to query the Twitter API with. Changing the keywords on thekeywordssheet allows you to query for different keywords.raw_data.zipcontains all of the raw tweets pulled back from the Twitter API.results.zipcontains csv files with sentiment, subjectivity, and phrase analysis scores.
Errors
-
The range in sentiment scores was only
0.2, which may be explained by just the time span in which tweets were collected, rather than the overall sentiment over time. - The range in subjectivity scores was only
0.10, which may be small enough to be accounted for in confidence errors by the subjectivity analysis model. - Since we did not have access to the Twitter's research API we were not able to search for tweets in all of Twitter's history, only within a set month. These results may be different than the results resulting from querying for tweets from all of Twitter's databases.
Further Research
Further research could be done in the following aspects:
- Instead of querying Twitter's API for tweets over the span of a month, query their overall database for tweets in all of time.
- The source code linked above could be adjusted to perform sentiment analysis on ANY project. All you would need to do is add your API developer keys and change keywords to search for!